How Websites Get Recommended by ChatGPT (And Why Yours Probably Doesn’t)
This guide is the practical version of that shift. We have spent the last two years rebuilding parts of clients’ content and technical strategies specifically for AI-mediated discovery, and the patterns of what actually gets cited — and what gets quietly ignored — are clearer than the surrounding noise suggests. If you want the full strategic context of how AEO, GEO, AIO and LLMO fit together, our complete AI search optimisation guide is the companion piece. This article focuses tightly on one question: why some websites get recommended by AI assistants and most do not.
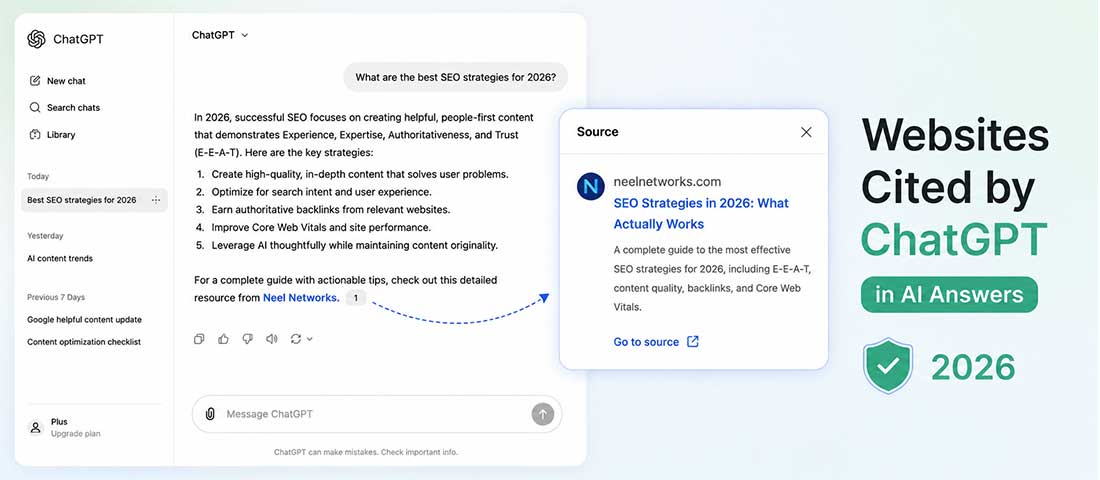
Why traditional SEO alone no longer cuts it
It is worth being honest about what traditional SEO is optimised for. It is optimised for getting a human to click a link on a results page. That means meta titles engineered for click-through, keyword density calibrated for crawlers, and backlink profiles built to signal authority to a ranking algorithm. All of it serves a single outcome: appearing in the top ten of a results page that a human will scan.
None of that directly translates to AI recommendations. When someone asks ChatGPT “what is the best project management software for a ten-person startup”, the model does not pull up a results page and pick the first link. It draws from its training data and, for some assistants, from live retrieval. It then synthesises an answer from the sources it considers reliable, well-structured and informative. A page optimised for a featured snippet with a fifty-word answer is not necessarily going to win. A page that thoroughly explains the trade-offs, names specific use cases and provides genuine value to a reader making that decision has a much better chance.
The underlying issue is that SEO as most practitioners still practise it treats content as a vehicle for keywords. AI systems treat content as a vehicle for knowledge. That distinction matters more than most businesses are willing to admit, and it is the reason teams that have invested heavily in traditional SEO can still find themselves missing from the AI-answer layer entirely. The traditional discipline still matters — strong SEO services remain the foundation for being findable at all — but on top of that foundation, a separate set of moves is needed to be the source an AI assistant actually cites.
How ChatGPT, Gemini, Claude and Perplexity actually choose sources
This is the part most articles on the topic get wrong by being either too vague (“just write good content”) or too speculative (endless guessing about training algorithms). The reality sits in between, and it is worth being clear about it.
Training data and what gets baked in
ChatGPT, built by OpenAI, and Claude, built by Anthropic, are both large language models trained on enormous datasets of text from the internet, books and other sources. When these models generate a response, they are drawing on patterns and information baked into their weights during training. Websites with high-quality, frequently-cited, clearly written content had a higher probability of being well-represented in that training data.
The practical implication is uncomfortable for businesses arriving late. If your site has been consistently producing expert-level content on a topic for years — content that other sites have linked to, quoted, or built on — your brand and your explanations are far more likely to surface in the model’s responses on that topic. If your authoritative content was published last month, it may not appear in trained-model answers until the next major training cycle, which can be many months away.
Retrieval-augmented generation and live search
Perplexity works differently. It performs a live web search for almost every query and synthesises the answer from the live results. Google’s Gemini also pulls from live search when needed. ChatGPT, depending on the configuration, can browse the web in real time. When these retrieval systems are active, the behaviour is closer to a very fast research assistant — and the factors that determine what gets cited look closer to a blend of traditional search signals and content quality signals than to anything purely about training data.
The practical implication is that your website needs to be both crawlable by these systems and genuinely informative to a reader. The two requirements are not in tension; they are the same requirement seen from two angles. Sites that solve one and not the other underperform on both. Our AIO, AEO and GEO services are specifically built to address both layers in a single coordinated programme rather than as separate workstreams.
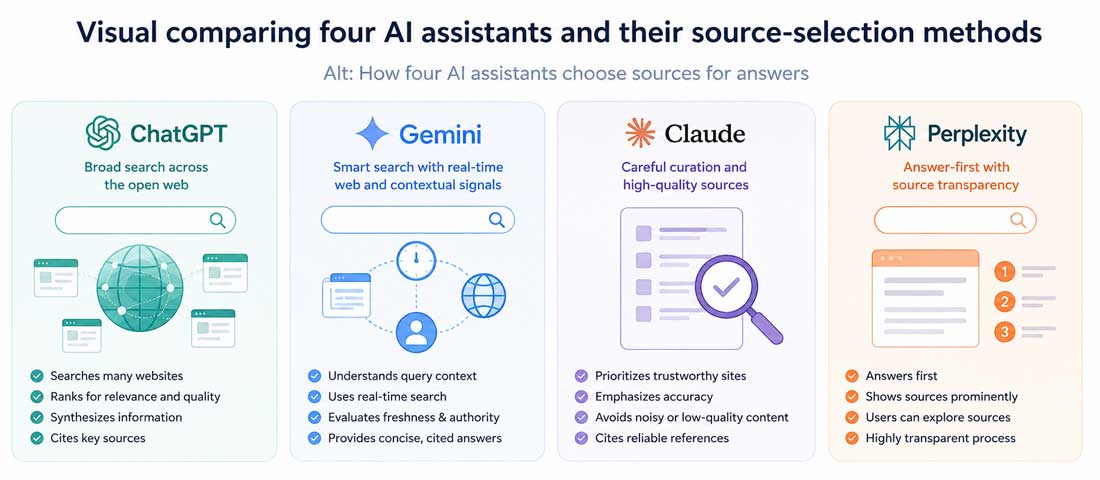
| AI system | Primary method | Key factor that matters |
|---|---|---|
| ChatGPT | Training data, optional live browsing | Depth of coverage in the training corpus |
| Google Gemini | Live search plus training | Search authority combined with content clarity |
| Claude | Training data | Information density and accuracy of the source |
| Perplexity | Live retrieval | Crawlability plus direct-answer formatting |
Why most websites never appear in AI answers
The hard truth is that most websites simply were not built to be useful to anyone outside a narrow SEO funnel. Four structural problems do most of the work in keeping them invisible to AI assistants, and all four are common.
Shallow content that answers nothing
Tens of thousands of blog posts exist that are technically fifteen-hundred words long but contain perhaps two hundred words of actual information, spread across padded introductions, obvious subpoints, and three versions of the same closing call to action. AI systems — the more capable ones especially — are good at identifying informational density. A page that meanders to its point and hedges every claim is not going to be synthesised into a useful answer, no matter how aggressively it ranks.
No topical depth or authority
Publishing one post about email marketing and then three posts about something unrelated does not establish a site as a resource on email marketing. AI systems look for signals of sustained, deep expertise in a specific domain. If a content archive looks scattered — some HR, some marketing, a product announcement, a hiring update — the site is not positioning itself as the kind of authoritative source a model should draw from for any particular question.
Poor structural clarity
Headings that do not describe the content below them. Paragraphs that mix multiple unrelated ideas. Content without clear answers to clear questions. All of this reduces the extractability of information. When a retrieval system or a model is trying to find the answer to a specific question on your page, it needs to be able to locate that answer quickly. Buried answers cost citations.
Lack of brand mentions and entity recognition
If nobody else on the internet is discussing your brand in relation to your area of expertise, you are essentially an unknown entity to models trained on that internet. Mentions in industry publications, references in roundups, citations in other blogs — these create the web of entity associations AI systems use to understand what a brand is, what it is known for, and whether it is worth recommending. A brand mentioned only on its own website looks, to the model, like a brand only its owners think exists.
The signals AI systems are actually evaluating
You cannot peer inside a model’s weights and read out a ranking checklist. But you can reason carefully about which content patterns are more likely to be well-represented in training data and surfaced in live retrieval. Five signals do most of the work.
Information density per paragraph. How much useful, specific information does each paragraph contain? A paragraph that defines a concept, gives a concrete example and names a specific implication is more information-dense than one that restates the heading in slightly different words. AI systems consistently favour the first kind.
Consistent topical focus. Over the lifetime of a domain, does the content consistently address a coherent topic area? Sites that go deep — publishing thorough guides, answering adjacent questions, covering the topic from multiple angles — are more likely to be treated as authoritative on that subject. Sites that drift across unrelated topics weaken every cluster.
Citation patterns from the wider web. Is this site being linked to and quoted by others in the field? This is not purely about backlink count, though that still helps for live retrieval. It is about whether the content is treated as a source rather than just another voice in the conversation. The entity-and-citation angle is one we covered in depth in our piece on how Reddit ranks and gets cited by AI, because the same logic applies on the broader web — the brands that get cited get recommended.
Directness of answers. Does the content actually answer the questions it raises? A page titled “how to calculate customer lifetime value” that does not include the formula, the explanation and a worked example is not answering the question — it is dancing around it. Direct, complete answers are far more likely to be quoted than evasive ones.
Author and entity credibility. Is the content written by identifiable experts? Does the about page name real people with real credentials? Are those people mentioned elsewhere on the internet in contexts relevant to the topic? These signals matter both to traditional search and to AI systems trying to decide whose answer to trust.
The content structure AI models prefer
The way content is structured has a direct impact on how usefully it can be processed — by AI systems and by humans. This is why information architecture and proper UI/UX design matter well beyond aesthetics. The patterns that work best share a common logic: they make information findable, extractable and quotable.
Question-first headings. Structuring H2 and H3 headings as the actual questions a user would ask (“what does customer lifetime value measure?”) rather than vague labels (“CLV explained”) creates direct alignment between what users ask and what your content answers. This is good for voice search, good for featured snippets, and good for AI extraction at the same time.
Direct-answer paragraphs. Immediately after a question-style heading, the first one or two sentences should contain the direct answer. The rest of the section then expands, qualifies and provides examples. Think of it as an inverted pyramid — answer first, context after. AI assistants reading the page can lift that first sentence cleanly as the citation; humans get the depth they need by reading on.
Defined terms. When you introduce a concept, define it explicitly. Not necessarily with a dictionary entry, but with a practical explanation that makes the meaning clear in context. AI systems synthesise much more accurately when terminology is consistently and clearly defined throughout a page.
Summary callouts and key takeaways. These do double work. For human readers they aid retention. For AI retrieval they are highly extractable chunks of high-signal content. A well-written callout is essentially a pre-packaged citation, easy for any system to lift cleanly.
Why most AI-generated blog content fails to rank in AI search
There is a particular irony in using AI writing tools to generate content hoping to rank in AI search systems. The outputs of undirected AI content generation — endless generic posts about “the importance of digital marketing” and “ten ways to improve your SEO” — are exactly the kind of noise the more sophisticated AI models are trained to see through.
The problem is not that AI wrote it. The problem is that it was written without genuine expertise informing it. A post on B2B SaaS pricing written by someone who has never negotiated an enterprise software contract reads differently from one written by a revenue leader who has lived through hundreds of those conversations. The difference is not always explicit. It shows up in the specific details, the unexpected caveats, the willingness to take a clear position, and the absence of hedging filler.
Large language models, trained on both excellent and poor writing across the internet, are better than most people expect at detecting informational thinness. The content that gets cited and recommended is content with earned opinions and specific knowledge — the kind that only comes from genuine experience or genuinely deep research. Whether a human or an AI assisted with the draft is much less important than whether the underlying knowledge is real.
Want Help Making Your Website Genuinely AI-visible?
If you would rather have an experienced team rebuild your content and technical foundations for AI search — schema, structure, topical depth, entity authority and the AI-crawler access most sites have wrong — we are happy to help. Send us your domain and we will come back with an honest read on where you stand within one business day.
Authority, trust and the role of brand mentions
Authority in AI search is not fundamentally different from authority in traditional search, but the mechanisms are slightly different. For systems trained on historical web data, your authority is built by how frequently and in what context your brand appears across the wider web.
A brand mentioned in a tier-one industry publication, cited in a research report, and referenced in ten thoughtful articles by practitioners in the field carries a different weight from a brand that has only ever spoken about itself on its own website. This is entity recognition at work — the model has “seen” your brand discussed in credible contexts, and has formed an association between your name and certain areas of expertise.
Building this kind of authority requires thinking beyond your own website. It means getting genuinely quoted in industry publications (not just submitting press releases), having your founders and senior team members publish and speak on credible platforms, earning backlinks through content that is actually worth citing, creating proprietary data or research or frameworks that others want to reference, and being mentioned in the comparison articles and category roundups your buyers read. None of this is fast. All of it compounds. Each credible mention strengthens the entity association that makes AI systems more likely to surface your brand in relevant conversations.
Semantic clarity and structured content
Semantic SEO has been discussed in traditional search circles for years, but it becomes even more important in the context of AI search. Semantic clarity means the meaning of your content is unambiguous — to human readers and to automated systems parsing it.
Practically, this means using entity names consistently rather than switching between near-synonyms (“project management software”, “task management tools” and “productivity apps” are not interchangeable — pick one and use it). Establishing clear relationships between things rather than just listing them (“tool A is better for teams over fifty; tool B suits solo operators and very small teams” is more useful and more citable than “both tools are good options”). Implementing schema markup correctly across the page types where it applies — FAQ, HowTo, Article, Organization, Author, LocalBusiness where relevant. And maintaining a consistent voice and a consistent depth across each content type, so that a single page does not mix shallow marketing copy with deep technical sections in ways that hurt summarisation.
The technical foundations that make AI visibility possible
Beyond content, there are technical factors that determine whether AI retrieval systems can even access your content in the first place. Get these wrong and the content itself will not matter, because nothing can be cited that nothing can read.

Crawlability. If important content is hidden behind JavaScript rendering that bots cannot process, or locked inside PDFs with no corresponding web page, it is not in the retrievable web. Both Perplexity and Gemini depend on crawlable web content for live retrieval. Every custom website built properly in 2026 is engineered for clean, crawlable output from day one rather than retrofitted later.
Page speed and Core Web Vitals. Slow pages are not just frustrating for users; they are more likely to be ranked lower in the underlying search signals feeding live-retrieval AI systems. The performance work that makes a site fast for visitors is the same work that keeps it competitive in the citation pool, and it has to be maintained continuously rather than fixed once.
Robots.txt and AI crawler permissions. Ironically, many websites have accidentally or deliberately restricted AI crawler access. OpenAI’s GPTBot, Anthropic’s ClaudeBot, Google-Extended and PerplexityBot are all identifiable user agents that have to be allowed access for the relevant systems to index your content. Some sites blocked these crawlers in 2024 as a privacy reflex and never reversed it. Those sites are now invisible to the entire AI-search layer. Check the file. Fix anything broken.
Clean URL structure and mobile optimisation. Descriptive, logical URLs — “yoursite.com/guide/customer-lifetime-value” rather than “yoursite.com/?p=2347” — help AI systems understand context before they even read the page. Mobile-first indexing is the actual index feeding most retrieval systems, and mobile optimisation is non-negotiable. This work overlaps almost entirely with what makes a site rank well in traditional search, which is why a properly built site rewards both layers simultaneously. The broader pattern of how AI is reshaping the search foundation underneath all this is covered in our piece on how AI is transforming SEO.
The common mistakes businesses keep making
The patterns of failure across the audits we run are remarkably consistent. None of these mistakes is exotic; all of them are quietly disqualifying businesses from AI visibility right now.

- Treating AI visibility as a future concern. The businesses already positioned in AI answers have been publishing high-quality, structured content for years. The compounding started a while ago. The next best moment to start is now.
- Publishing AI-generated content at scale without editorial judgement. Volume does not build authority. A hundred thin posts produce a lot of words and very little knowledge. Ten genuinely excellent deep dives are worth more.
- Ignoring off-site entity building. A content strategy that lives entirely on your own domain produces a brand the wider web has never heard of. Without external mentions and citations, you are unknown to the systems trained on that web.
- Skipping structured data implementation. Schema is not optional for businesses serious about AI visibility. It is the machine-readable layer that tells systems what your content is and what questions it answers.
- Blocking AI crawlers in robots.txt. Some sites blocked GPTBot or ClaudeBot in 2024 as a reflex and never undid it. Those sites are now invisible to ChatGPT and Claude entirely. Audit the file.
- Burying answers deep in the page. If the answer to a question is in paragraph five, the model will not find it. The first sentence under every question heading has to carry the answer.
- Hedging every claim with qualifiers. Models reward sources that take clear positions. A page that hedges every sentence reads as low-confidence and gets passed over in favour of sources that commit.
- Mixing depth levels within one page. A page that swings between shallow marketing copy and deep technical detail confuses summarisation. Pick a depth and hold it through the page.
The seven steps to actually make your website AI-visible
The diagnosis above tells you what is wrong with most websites. The seven steps below are the practical work that fixes it, in the order we run it for clients. Each step builds on the one before it.
-
Audit your existing content for informational depth
Go through your most important pages and ask the honest question — does this page actually answer the question it claims to address? If the answer is partial, hedged, or padded, either rewrite it to genuinely answer the question or consolidate it into a stronger page that does. Thin content drags down the perception of the whole domain; cutting or improving it lifts the rest. -
Identify your topical authority zone
Pick the three to five topics where you have genuine expertise and commit to producing the most thorough, accurate and useful content on the web in those specific areas. Spreading effort across twenty topics produces shallow coverage everywhere. Concentrating effort across five topics produces the depth that earns citations. -
Restructure for extractability
Add direct-answer paragraphs after question-style headings. Create summary callouts for key insights. Implement FAQ sections at the bottom of longer guides. Make it easy for any retrieval system — human or AI — to locate the specific information a user is looking for in under ten seconds. -
Build your entity presence off-site
Pursue genuine coverage in industry publications, contribute to roundups from a position of real expertise, get your founders and senior team published and quoted on credible platforms, and create original research that others in your field will want to reference. Each external mention strengthens the entity associations that AI systems use to decide whose answer to trust. -
Implement schema markup properly
At minimum: Article schema on editorial content, FAQPage schema where the page answers specific questions, Organization schema sitewide, Author schema linking to credible author pages, LocalBusiness schema for any business with a physical presence. HowTo and Product schema where relevant. Valid, complete, and consistent — broken schema is worse than no schema. -
Unblock the AI crawlers
Open your robots.txt and check it for rules that block GPTBot, ClaudeBot, Google-Extended, PerplexityBot or any other AI user agent. Unless you have a specific legal reason to keep them out, allow access. Without it, your content is not eligible to be cited by the systems that need to crawl it. -
Publish original data and named frameworks
Create content that is inherently citable — original survey data, proprietary frameworks, named methodologies, benchmarking studies. These are the formats other publications quote and link, which generates the external references that strengthen your entity associations and feed the long compounding loop of AI-visibility growth.
Where AI search is heading next
The direction of travel is clear. AI-mediated discovery is going to keep growing, and the definition of what it means to “rank” online is shifting from “appear in a list of links” to “be cited or recommended by an AI assistant inside a relevant conversation”. This is not the end of traditional search — Google is not going anywhere, and neither is the link-based web — but the new layer being built on top of it rewards different things.
It rewards knowledge over keyword coverage. It rewards structure over volume. It rewards genuine authority over engineered link profiles. The businesses that move quickly to align their content strategy with these realities will find themselves with a meaningful advantage in AI recommendations and, almost as a side effect, in the underlying content quality that makes them worth recommending in the first place. The work that wins AI search is the same work that wins durable organic discovery for the rest of this decade.
The question “how do I get ChatGPT to recommend my website” has a deceptively simple answer underneath all the technical detail — be genuinely worth recommending. Build content a thoughtful person would trust, that a researcher would cite, and that an expert would recognise as accurate and useful. Structure it so any system, human or automated, can extract the value from it quickly. The technical optimisations matter and the schema markup matters and the crawlability matters, but none of it substitutes for the foundational work of actually having something worth saying and saying it with the clarity and depth that makes it a genuine resource. The websites AI systems recommend are not gaming a new algorithm. They built something real, and the new systems are smart enough to recognise it.
Frequently asked questions
| Does a well-designed website help get recommended by ChatGPT or Perplexity? | Yes, but not in the way most people assume. AI systems do not see how a website looks visually — they process how it is structured. A site built with proper headings, direct answers, clean code, valid schema markup and fast performance is far more likely to be indexed and cited than one that is visually polished but structurally weak. Good design helps when the design translates into structural clarity, fast load times and clean crawlable output. Visual appeal alone does not, which is why design and technical engineering have to be planned together rather than as separate workstreams. |
| What is the difference between SEO and AEO or GEO, and which do I need? | Traditional SEO is optimised for getting humans to click a link on a search results page. AEO and GEO — answer engine optimisation and generative engine optimisation — are optimised for getting AI systems to cite or recommend your content inside their generated answers. Most businesses now need both. SEO keeps you visible in traditional search; AEO and GEO build your presence in the AI-mediated layer growing on top of it. The two disciplines share many foundations — structured content, schema, technical health — and pull apart in the content patterns each one rewards. |
| Can AI chatbots recommend my website if it is newly launched? | It depends on which AI system. For models like ChatGPT and Claude that rely heavily on training data, a brand-new website will not appear in answers until it has been included in a later training cycle, which can be many months away. For retrieval-based systems like Perplexity and Google’s AI Overviews, a new site can appear relatively quickly if it is properly crawlable, structured and ranks in the underlying search index. The practical move is to start building topical authority and technical structure from day one, even though the LLM-training-data dimension of visibility takes longer to materialise. |
| Is AI-generated blog content bad for AI search visibility? | Not inherently — but undirected, generic AI content almost always is. The problem is that AI writing tools, without genuine expert input, tend to produce information-thin content: lots of words and very little specific knowledge. AI search systems are particularly good at detecting that thinness. Content that gets cited has earned opinions, specific details and real expertise behind it, regardless of whether a human or an AI wrote the first draft. The bar is editorial quality and informational depth, not who produced the initial words. |
| Does schema markup actually influence whether AI systems recommend my website? | For LLM training data the influence is hard to verify directly. For retrieval-based systems like Perplexity and Google’s AI Overviews, schema markup — particularly FAQPage, HowTo, Article, Organization and Author schema — provides explicit, machine-readable signals about what your content is and what questions it answers, with a measurable effect on featured snippet eligibility and AI Overview inclusion. If your current site is missing structured data, that is one of the highest-return fixes available, and it tends to surface other foundation gaps worth addressing at the same time. |
| How do I know if my website is blocking AI crawlers? | Open your robots.txt — it usually lives at yourdomain.com/robots.txt — and check it for Disallow rules that target OpenAI’s GPTBot, Anthropic’s ClaudeBot, Google-Extended or PerplexityBot. If any of those crawlers are blocked, your content is not being indexed by the corresponding system. Many sites accidentally blocked AI crawlers through overly broad rules written for older bots, and the block was never reviewed. Reviewing and fixing this is part of any proper technical SEO and AI-visibility audit, and the fix itself usually takes minutes once the issue is identified. |
| My website has lots of content but never appears in AI answers. Why? | Volume alone does not create AI visibility. The most common reasons content-heavy sites still do not appear in AI answers are a lack of topical depth and authority (lots of posts but no concentrated subject expertise), answers that are buried or hedged rather than stated directly, content that is not cited or referenced by other reputable sources on the wider web, and weak technical infrastructure — missing schema, slow performance, blocked crawlers. A full AI-visibility audit usually identifies which of these is driving the gap and the relative size of each, so the fixes can be sequenced rather than attempted all at once. |
Ready to Make Your Website AI-visible — Properly?
We build AI-search-ready websites and run ongoing programmes covering the full picture — technical foundations, schema, content restructure, topical authority and the entity-building work that makes AI assistants cite your brand. With 12+ years of experience and over 2,500 websites delivered, we know what actually moves the needle. Send us your domain and we will respond within one business day.